
A recent paper from Stanford has sent shockwaves through the AI community that claims to offer a unifying theory of generalization in deep learning. The research suggests a new framework that explains why enormous, overparameterized models can still learn effectively without simply memorizing the data they’re trained on. This has remained a key mystery in the field of deep learning theory.
Table of Contents
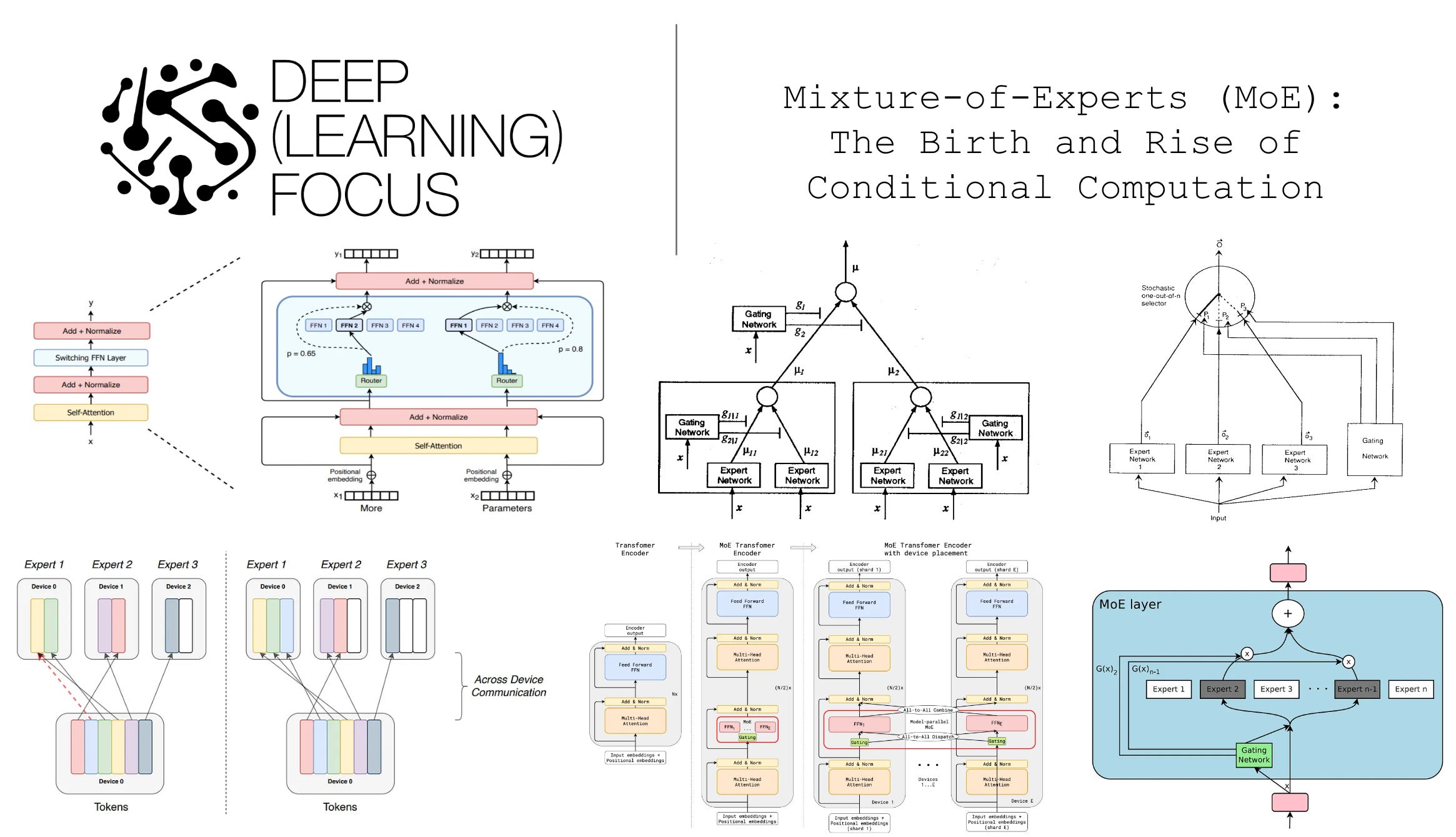
As outlined in a recent talk, this new approach to the technology uses the neural tangent kernel to create a clean “signal channel” while isolating noisy data. The authors claim this single idea can unify disparate phenomena like benign overfitting, double descent, and grokking. However, as of May 30, 2026, a deeper investigation reveals a more complicated and potentially risky picture.
What Really Explains AI’s ‘Magic’?
The core mystery that the field has grappled with is why these massive models work so well. We build neural networks with billions or even trillions of parameters—far more than needed to just memorize the training data. Despite this, they show an amazing ability to generalize to novel inputs. This puzzle is the heart of this innovation.
Researchers have documented strange behaviors such as “double descent,” where performance dips and then recovers as models get larger, challenging the classical understanding of statistics. The race to find a grand unified theory to explain all this is fiercely competitive for top academic and corporate labs, from Stanford University to Google’s DeepMind.
Having a strong position in this field requires more than just massive server farms; it demands a deep theoretical grasp. of the system is the real differentiator. A proven theory could unlock more efficient training methods, more reliable models, and a significant commercial advantage. This is precisely what makes the new Stanford paper so tantalizing, and why its claims demand such rigorous scrutiny.
You might also like: Soft robotics: The Breakthrough Facing a Critical Test
Stanford’s NTK Theory Under the Microscope
The Stanford team’s argument is built entirely upon the Neural Tangent Kernel (NTK), a theoretical bridge between deep learning and older kernel machines. The authors’ key insight is that during training, this kernel structure effectively creates a “signal channel” for the learnable pattern and a “reservoir” that harmlessly contains noise and prevents it from interfering with generalization.
The initial impression is that this is a breakthrough explanation. It provides a single mechanism that could account for why models can “grok” a solution long after achieving perfect training accuracy. The accompanying presentation, found on YouTube, makes a compelling case for this new perspective on it.
Unfortunately, the reliance on the NTK framework introduces some well-known and critical problems. The NTK model assumes networks are infinitely wide, which is a useful mathematical trick but a poor approximation of reality. Most importantly, this framework struggles to explain “feature learning”—the process where the network learns new, hierarchical representations of the data. This is arguably the most powerful aspect of deep learning, and any the platform that sidesteps it is fundamentally incomplete.
When Theories Collide: The Next AI Debate
The theoretical gap is made even more apparent by the divergent research paths taken by some of the industry’s pioneers. For instance, Geoffrey Hinton, a foundational figure in deep learning, has been actively promoting alternative architectures like the Forward-Forward Algorithm. Hinton’s research implies that backpropagation itself—the bedrock of the Stanford the technology proposal—could be a historical accident rather than a fundamental principle.
The lack of consensus on a core this innovation creates a nightmare for safety and regulatory efforts. If the creators of the technology have no unified theory for its behavior, how can regulators possibly create effective rules?
Organizations like the National Institute of Standards and Technology (NIST) are tasked with creating frameworks for trustworthy and explainable AI. Yet, without a robust and universally accepted the system, their efforts are akin to trying to write building codes without a theory of physics. The Stanford theory, while mathematically interesting, does not resolve this tension; in some ways, by highlighting the limitations of our knowledge, it sharpens it.
Related article: 3d silicon chip: The Breakthrough That Could Reshape Computing
The Bottom Line on deep learning theory
To conclude, while the Stanford paper is a notable academic achievement, it is not the grand unifying theory that the initial hype might suggest. It offers a compelling lens through which to view specific phenomena within the NTK regime, but it falls short of explaining the full picture of what makes deep learning effective, particularly concerning feature learning. The pursuit of a complete deep learning theory is far from over.
For developers, executives, and policymakers, the key is to separate the mathematical elegance from the practical reality. This theory provides a potential method to “suppress memorization,” but its reliance on an idealized framework means its real-world applicability is still an open and critical question.
Critical Signals to Watch:
- Watch for: Any follow-up papers that test the “signal channel” hypothesis on finite-width, production-scale models.
- Pay attention to: Public responses or critiques from researchers at competing labs like DeepMind, Meta AI, or Anthropic.
- Expect: Commentary from figures like Yann LeCun or Geoffrey Hinton that directly addresses the claims of this NTK-based theory.
- Keep an eye on: The emergence of practical tools or training algorithms that explicitly claim to leverage this “signal reservoir” concept.
- Evaluate: Progress in non-backpropagation-based models, which could represent a paradigm shift away from the entire foundation of this deep learning theory.